网上营业厅
掌上营业厅



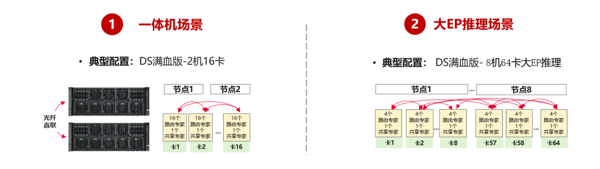
当前,DeepSeek已全面迈入大规模应用阶段,推理需求呈现爆发式增长,高性价比的推理方案炙手可热。在国家加速构建自主创新算力体系的战略背景下,中国电信携手华为开展核心技术攻关,星辰MaaS平台+昇腾解锁DeepSeek超强推理能力,完成DeepSeek模型基于昇腾大规模专家并行(后文简称“大EP”)解决方案的验证,以硬核实力重塑AI推理新标杆,以高效率赋能千行百业!
大规模专家并行推理(Large-Scale Expert Parallel Inference)是一种针对大规模深度学习模型的高效推理技术,尤其适用于DeepSeek-R1等基于混合专家架构的大模型。“专家”即混合专家MOE架构中的功能性子模型,通过分工协作实现高效计算和更强的任务处理能力。
该推理技术的核心思想是将模型中的多个“专家”子网络分布到不同的AI卡上,降低单卡的计算和内存压力,通过并行计算和动态路由机制,实现高并发、高吞吐、低时延的推理性能。
在大EP方案实施过程中,涉及到多专家的协同和调度、跨节点通信等难题:
通信开销,“网络拥堵”
“专家并行化”需要节点间频繁通信,但如果专家很多,将造成通信频次过高,形成类似交通拥堵的资源竞争状态,大量时间将消耗在通信等待中。
专家分配:负载失衡
在动态路由机制下,数据被动态分配给专家,可能出现“明星专家”被疯狂投喂任务,而其他专家模块处于低负载闲置状态。
系统复杂,协同瓶颈
在大规模部署时,跨专家协作、容错与资源调度的协同管理,成为关键的“工程瓶颈”。
三大核“芯”术 智算提效破局
若上述难题未得到有效解决,“专家并行化”的潜力将难以充分释放。为此,亟需通过新的算法优化和系统设计,以降低通信成本、实现智能负载均衡,并构建更鲁棒的分布式训练框架。中国电信联合昇腾利用三大黑科技,让智算资源效率大大提升:
PD分离(预填充和解码分离)
PD分离技术作为一种创新的架构设计,通过将大模型推理过程分解为两个独立的阶段,并针对每个阶段的特性进行专门优化,如同将“仓库与加工车间分开”,能够有效提升系统资源利用率。
多专家并行优化(智能任务调度)
“让专业的人做专业的事”,系统将图像识别、文本理解等不同任务分配给对应领域的专家处理。同时采用亲和部署策略,将高频通信的模块尽量部署在同一台物理设备上,减少通信开销。实测表明,资源利用率可提升20%。
融合算子(复合计算加速技术)
MLAPO(加速算子)将13个小算子融合成一个超级大算子,如同“产线工人升级为全流程操作手”,单次计算的同时能完成多项操作。在DeepSeek模型的量化场景下,该技术使计算耗时从109微秒缩减为45微秒,计算速度提升70%。
双场景实战 性能飙升四倍
在实战环境中,本次实验基于星辰MaaS平台,分别采用传统混合部署方案和大EP专家并行方案,基于DeepSeek R1进行推理性能测试,如下:
在输入2K、输出2K场景下
单卡平均端到端吞吐提升3.71倍;适合在线客服、智能问答等高频短文本交互。
在输入4K、输出2K场景下
单卡平均端到端吞吐提升3.53倍;攻克长文档摘要、代码生成等企业级刚需。
经过实测验证,单卡吞吐性能提升近4倍!
多维度应用 实现“算力自由”
在互联网、科技行业,大EP方案特别适用于高并发场景,如智能客服和AI内容生成。相比传统GPU集群,该方案能大幅降低单卡显存占用,支持更高的用户请求并发量,提升响应速度与用户体验,同时降低50%以上的硬件成本。
对于金融、要客等对数据隐私要求严格的行业,大EP方案支持私有化部署,通过多专家并行技术,可在保持同等推理性能的情况下减少40%的AI卡投入,既满足国产化要求,又显著降低硬件投资成本,缩短回报周期。
此外,星辰MaaS平台提供开箱即用的大EP方案,适用于政务、农业、文宣等行业,用户无需自建算力,通过API即可快速集成,实现零运维、按需付费的弹性服务,整体成本仅为自建算力的1/3,尤其适合预算有限但需要高并发支持的场景。
无论是互联网大模型的高并发推理,还是企业私有化大模型的服务,大EP方案都能以更低成本、更高效率满足大规模推理并发性能需求。国产智算+自研技术,加速AI推理规模应用,真正实现“算力自由”!
中国电信星辰MaaS平台+星辰行业智能体平台+DeepSeek+昇腾大EP方案,为企业客户提供一站式算力+数据+模型+平台+应用端到端解决方案及极致性能推理服务,让AI应用的搭建快速、简捷,高效。

 新浪微博
新浪微博 今日头条
今日头条 腾讯微信
腾讯微信

