网上营业厅
掌上营业厅


近日,天翼云上线全球运营商首个商用昇腾大规模专家并行(大EP)推理集群,结合息壤MaaS支持提供万亿级Tokens日调用,支撑用户国产化智算应用全面用云。自2025年初以来,DeepSeek大模型凭借其超高训练性价比、高推理性能掀起了全民AI热潮,人工智能全面迈入大规模应用阶段,推理应用在各行业全面加速落地,Tokens处理需求量与日俱增,这对推理系统的性能提出了更高的要求。为应对这一挑战,大规模专家并行推理技术与PD分离技术应运而生,为大模型推理应用的加速规模应用提供了强大的技术支撑。
大规模跨节点专家并行技术(简称大EP) 是一种针对大规模深度学习MoE模型(如DeepSeek)的高效推理技术,可对推理路由专家进行大规模EP并行、对MLA和共享专家进行DP并行,并进行双流并行通信掩盖,同时降低模型权重占用的NPU内存,提升KV Cache缓存空间,增加整个集群的吞吐。PD分离技术是指将推理过程中的Prefill计算和Decode计算分开。Prefill和Decode两者计算类型不同:Prefill为计算密集型,时延主要由算力决定;Decode为访存带宽密集型,时延主要由访存带宽决定。PD混合部署时,两者互相干扰:Prefill时,Decode等待;Decode时,Prefill时延增加,P/D时延不稳定,资源需求更大。PD分离部署时,Prefill阶段和Decode阶段分别部署于不同的物理节点,两者并行计算以实现硬件平均吞吐效率的有效提升。
 PD混合部署示意图
PD混合部署示意图
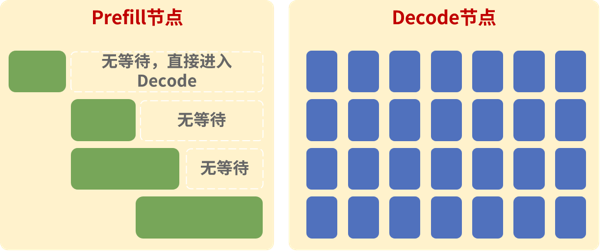 PD分离部署示意图
PD分离部署示意图
天翼云携手昇腾围绕大EP与PD分离技术进行深度创新,将DeepSeek 671B满血版大模型按专家维度切分到不同的NPU上,使得单卡权重占用内存比例大幅降低,权重加载耗时大幅减少,且可用于KV数据计算的内存显著增加,实现高并发、高吞吐、低时延的推理性能。在大EP方案实施过程中,双方联合解决多专家的协同调度、跨节点通信拥塞等难题,实现推理API服务调用三级负载均衡:
· API server层实现流式与非流式请求分离;
· 在P/D节点实现推理请求实例级负载均衡调度;
· 专家级负载均衡实时动态调整冗余专家来分担负荷,有效避免计算资源浪费,结合专家亲和部署,降低通信量30%。
天翼云昇腾大EP推理集群在输入1K、输出1K场景与输入2K、输出2K场景下单卡平均端到端吞吐均提升3.8倍左右;在输入5K、输出2K场景下,单卡平均端到端吞吐提升5倍以上,满足长文档等刚性需求;相比于传统DeepSeek双机部署方式,支持3倍以上的用户并发量,更好服务于客户智能化转型。
天翼云MaaS提供大模型服务的开发者平台,提供功能丰富、安全以及高性价比的模型调用服务,同时提供数据集、精调、评测等端到端能力,以及RAG、联网搜索等插件服务,全方位保障模型服务的开发与落地。
天翼云始终坚持以科技创新为根本,坚定不移走自主可控之路,持续夯实国产云底座,与时俱进,开拓创新满足各行业多元化业务场景需求。在新时代AI发展浪潮中,引领先进技术的前进方向,不断优化性能,突破创新,为AI智算发展贡献强劲动力,服务于千行百业,共创未来。

 新浪微博
新浪微博 今日头条
今日头条 腾讯微信
腾讯微信

